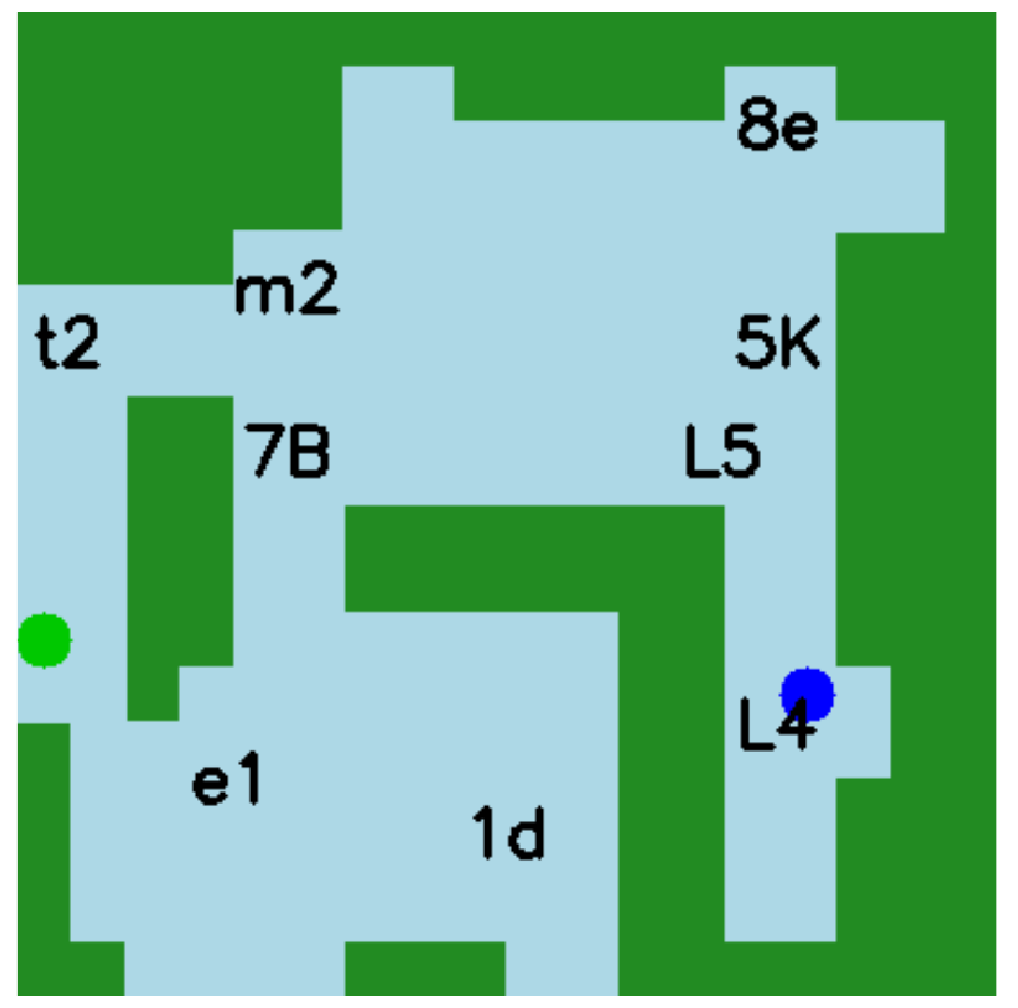
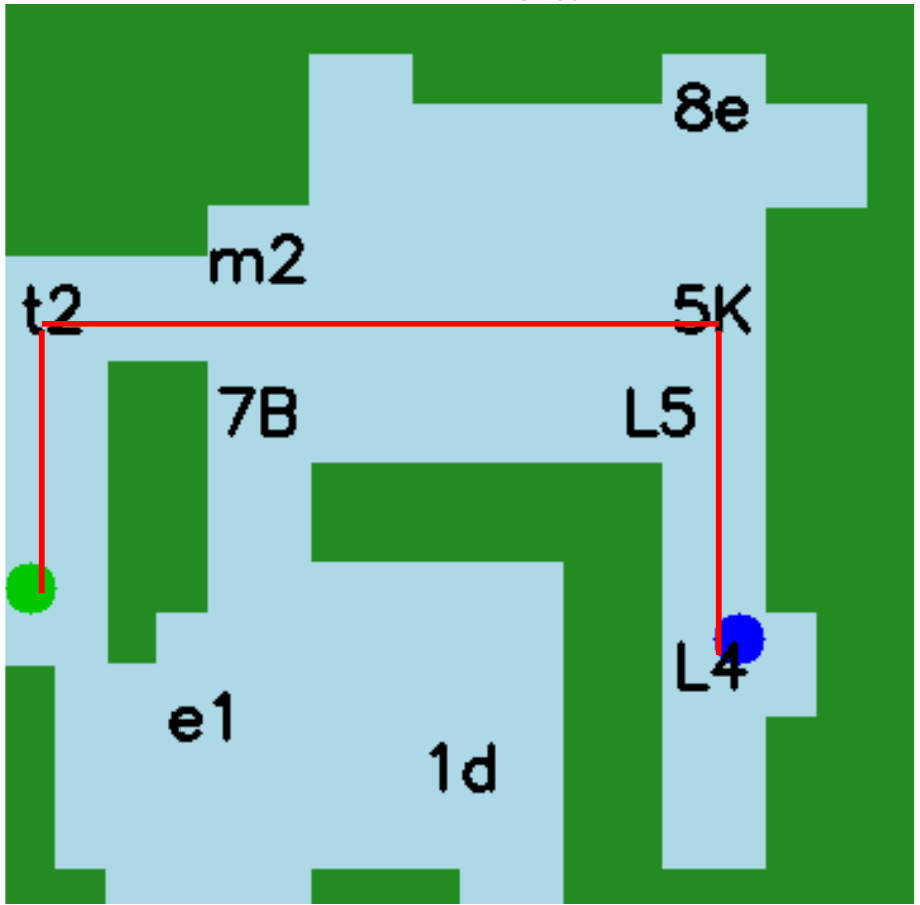
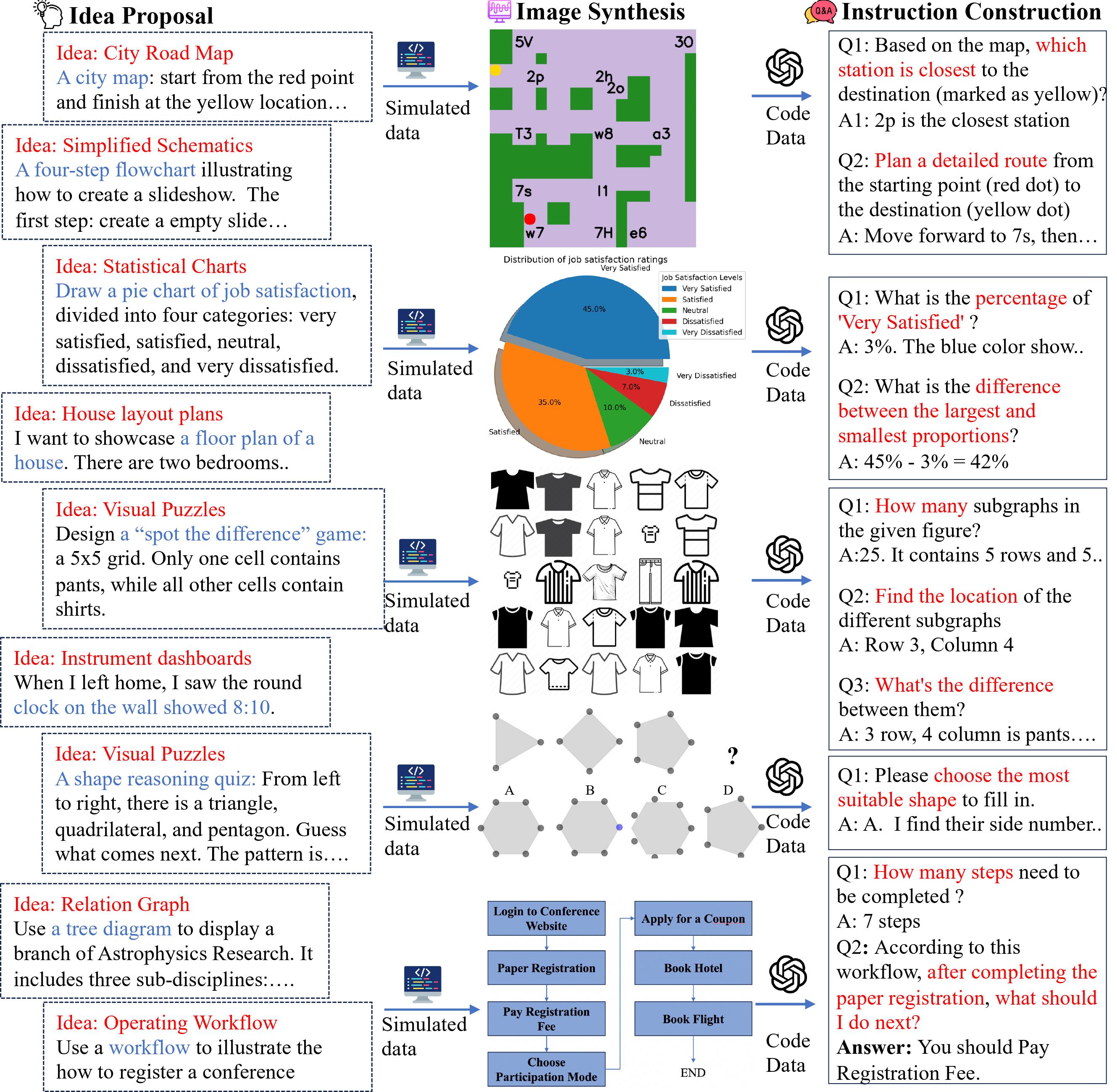
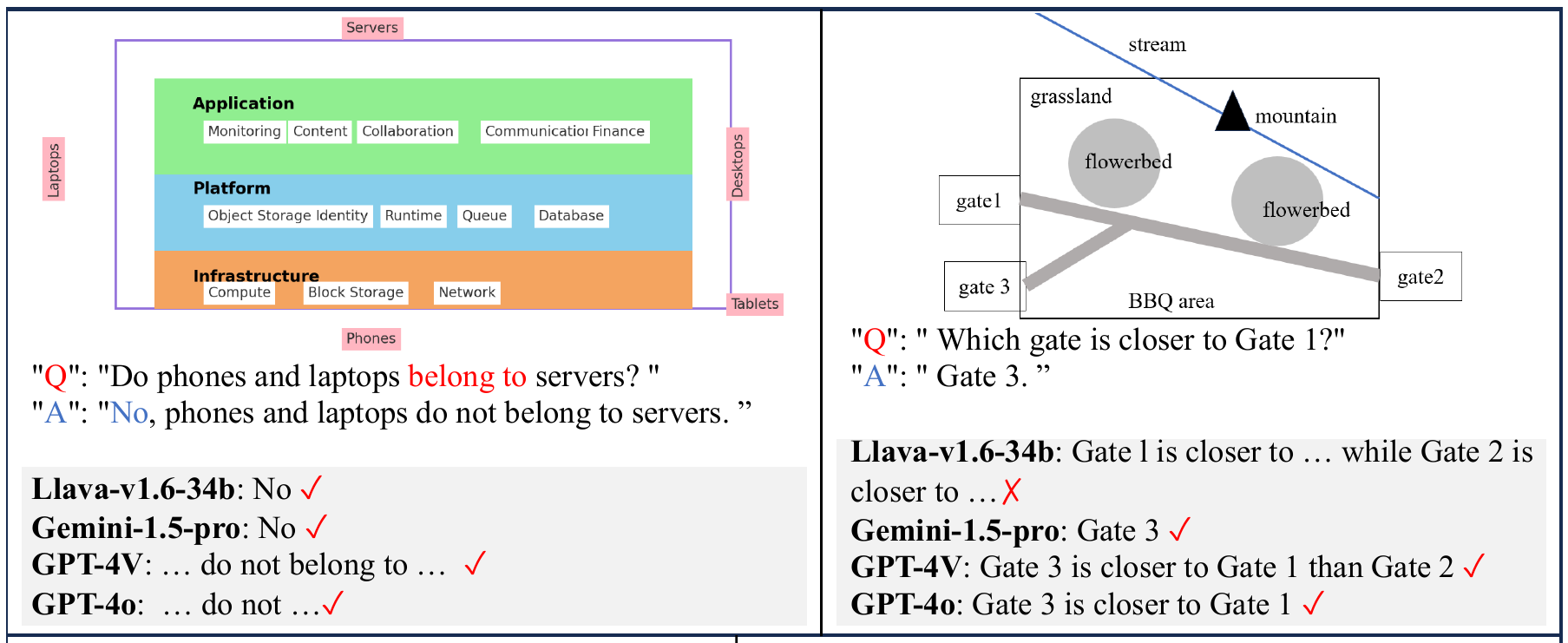
Chart
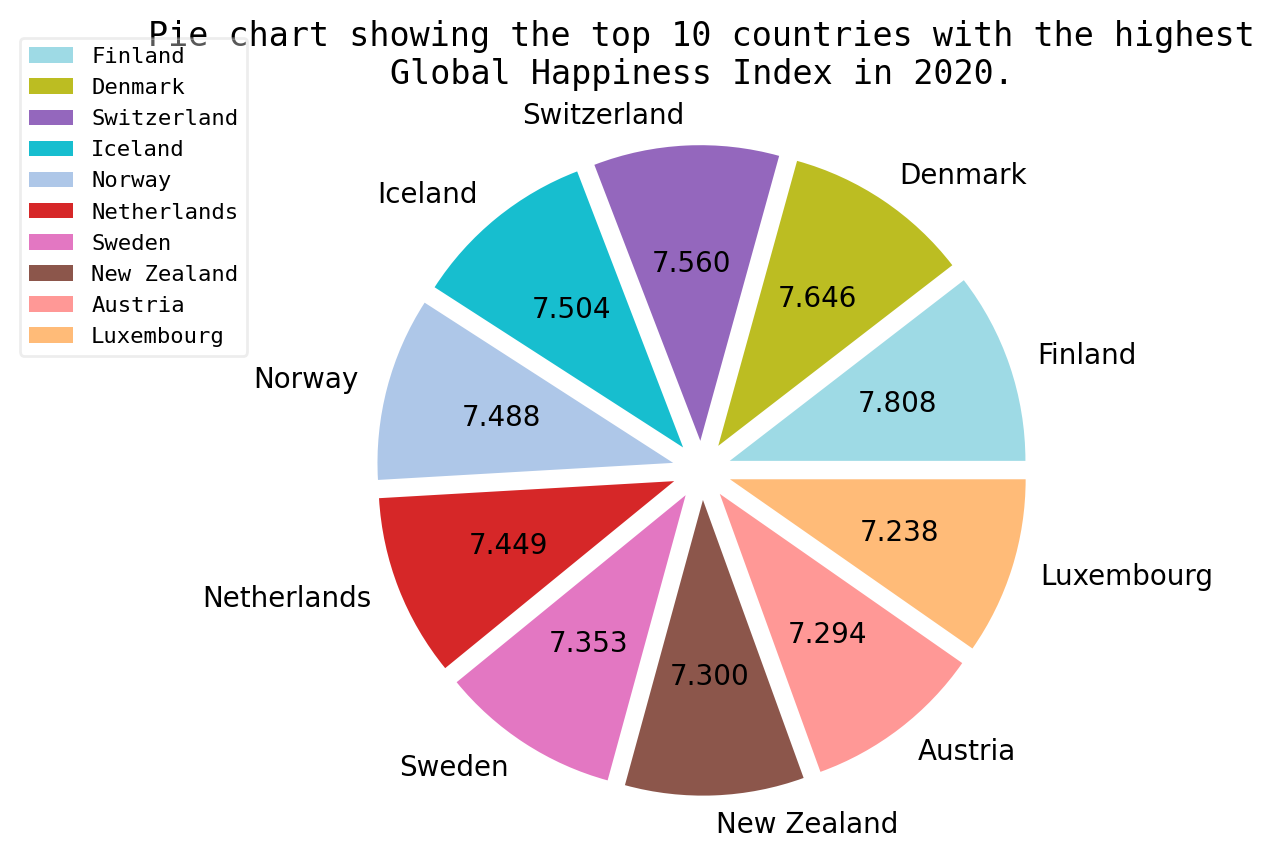
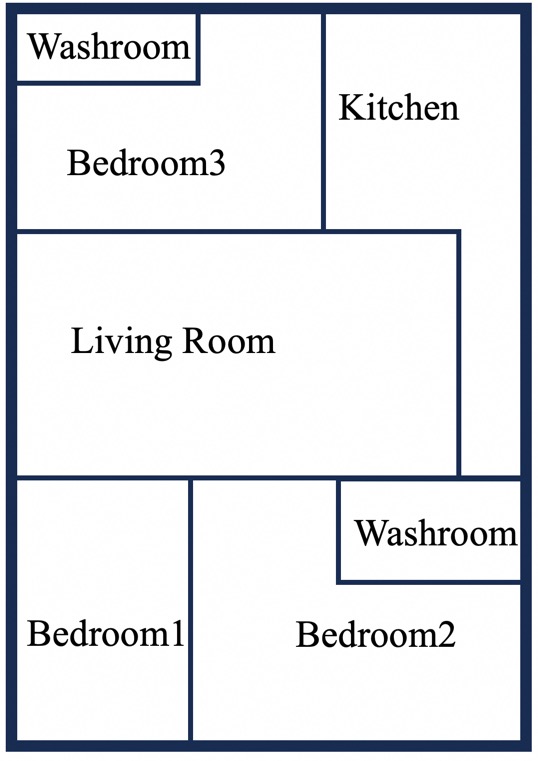
"Q": "Which country has the highest Happiness Index?",
"A": "Finland"
Llava-v1.6-34b: Finland ✔
Gemini-1.5-pro: Finland ✔
GPT-4V: Finland ✔
GPT-4o: Finland ✔
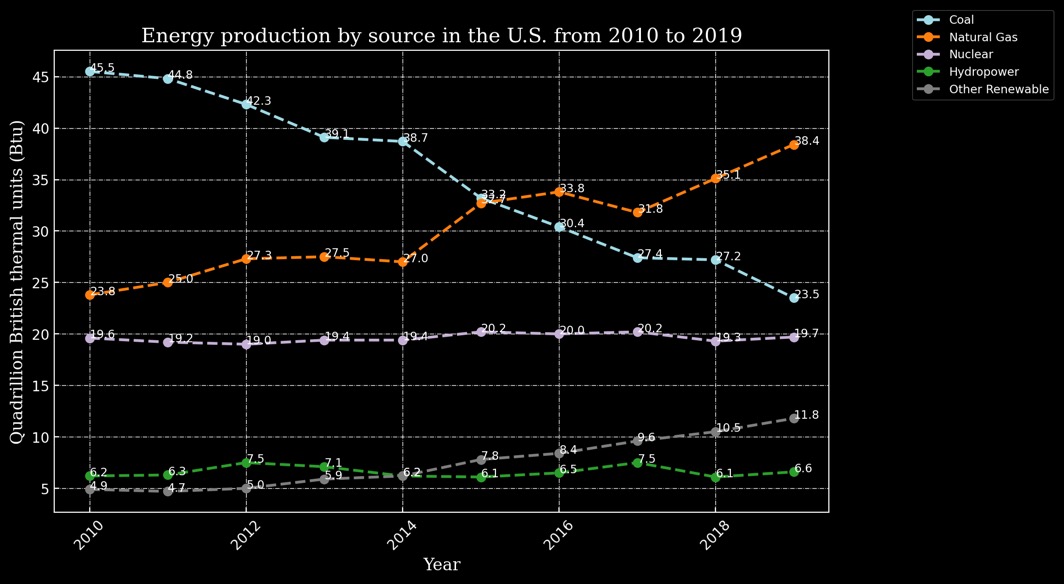
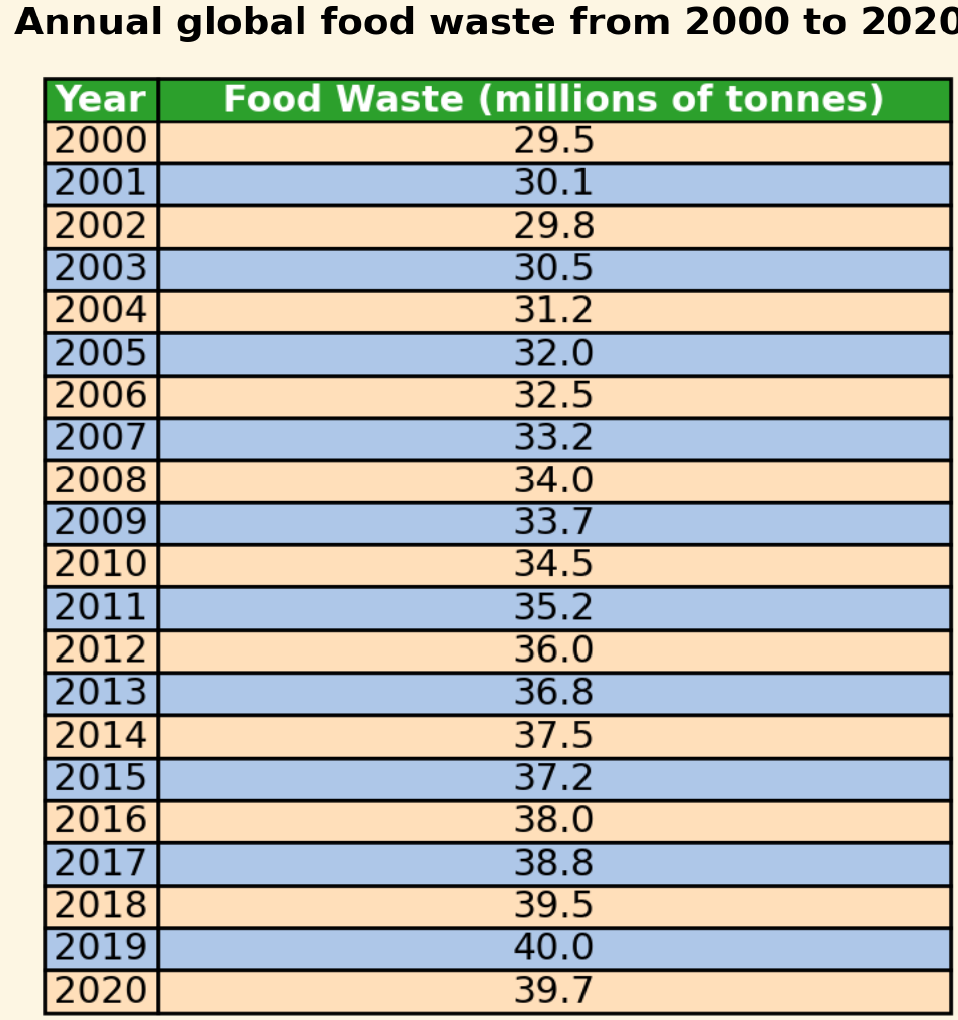
"Q": "What is the difference between the highest and lowest energy production from natural
gas?",
"A": "14.6 Quadrillion Btu",
"Rationale": "... subtract the smallest value from the largest... 38.4 - 23.8 = 14.6
Quadrillion Btu"
Gemini-1.5-pro: highest … approximately 38. lowest …
approximately 24… The difference is approximately 14 …✔
GPT-4o: The highest…approximately 44, and the
lowest…about 22. the difference … approximately 22 ✗